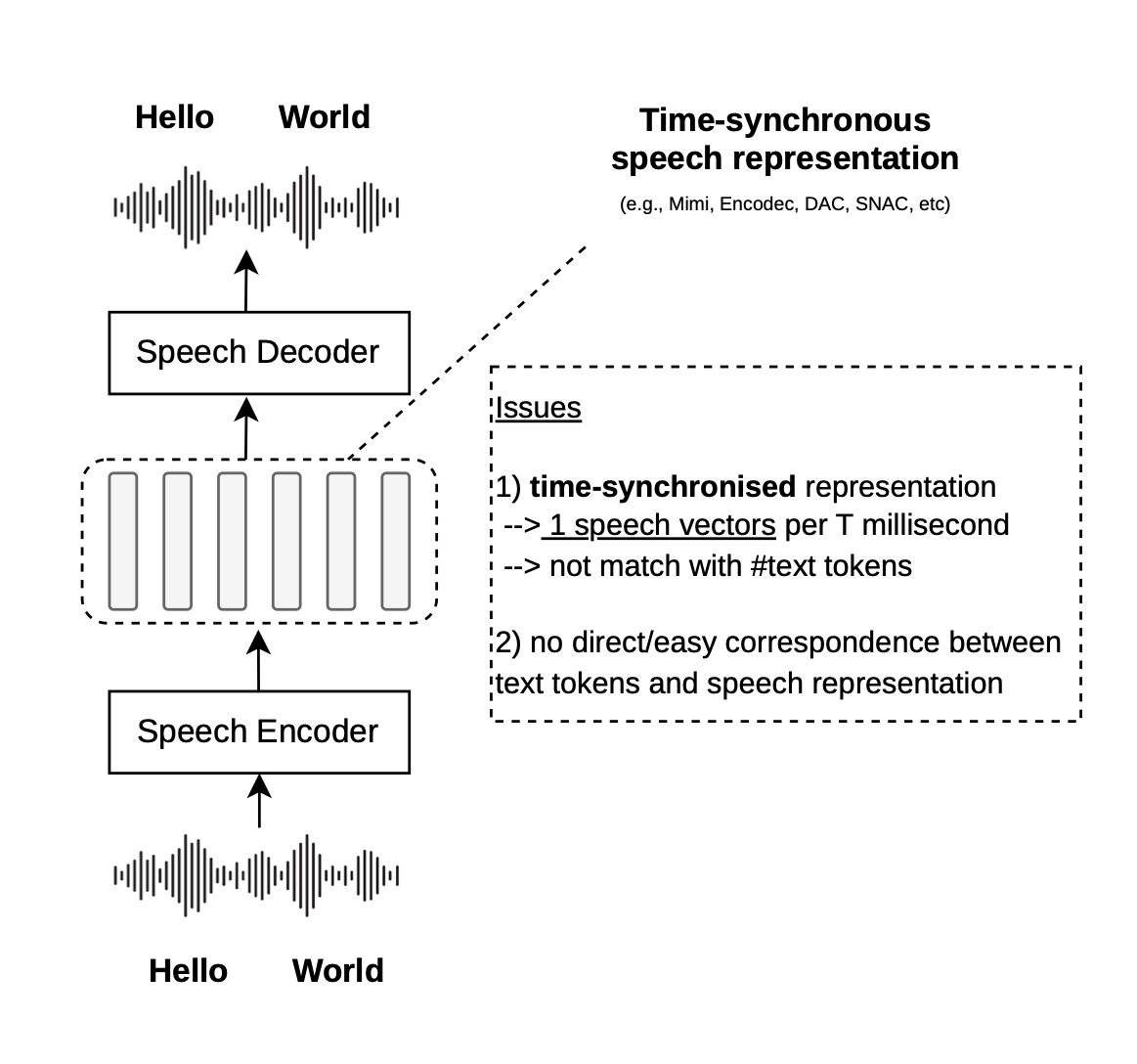
Speech embeddings (i.e., encoders) map raw audio waveforms into sequences of continuous vectors that represent fixed time intervals (e.g., one vector every 80ms)—time-synchronous representations. While this works well for speech processing, LLMs operate in a different temporal space: they process semantic concepts as discrete text tokens (e.g., one vector for a subword)—text-synchronous representations. This mismatch could make it more difficult to build multimodal speech-text LLMs. For example, Moshi, SyncLLM, SALMONN-Omni operate in time (e.g., one step = fixed ms), while Llama-Omni2, Qwen3-Omni, and LLM-based TTS (e.g., CSM, OrpheusTTS) mix time and text tokens.
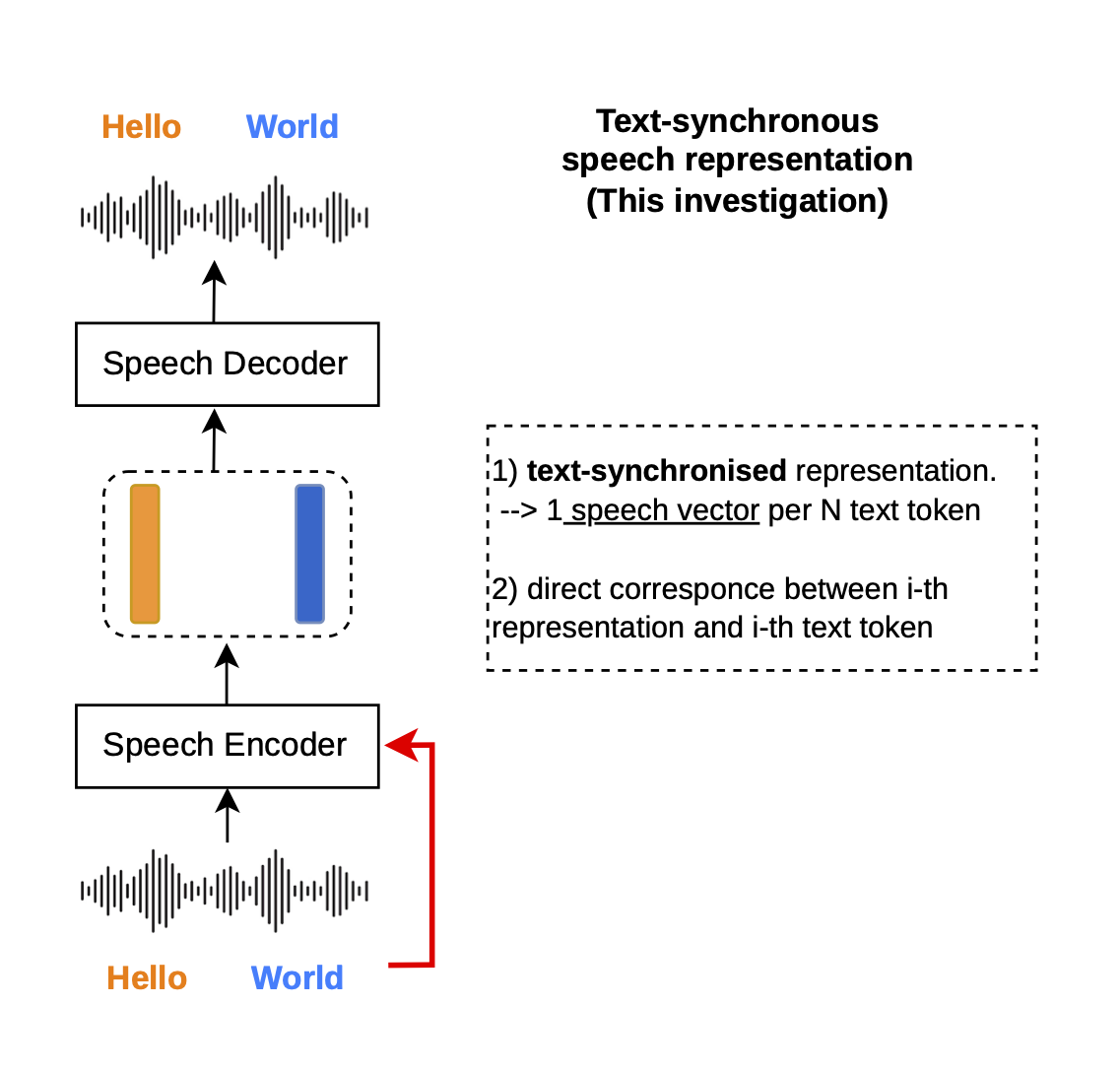
We ask: "can we turn[1] existing time-synchronous speech representations into text-synchronous ones?"
[1] Training a new speech embedding tokenizer from scratch requires massive data (e.g., Mimi was trained on 7M hours of speech), and this work focuses on adapting existing ones (e.g., with around 1K hours of speech).
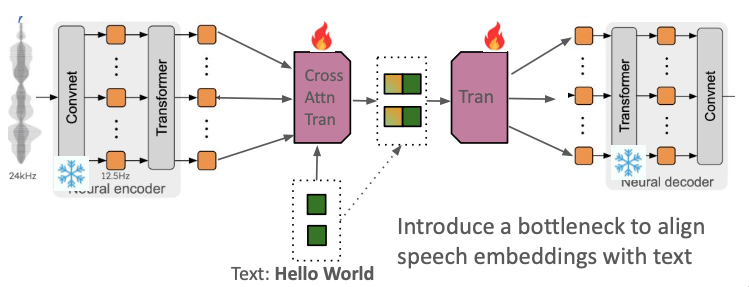
To transform these representations, we introduce an Additional Encoder and an Additional Decoder built on top of an existing speech tokenizer, where we use Mimi as an example in this work.
The speech encoder of Mimi operates at 12.5 Hz (i.e., yielding one representation every 80 ms), which is discretized by an RVQ network with 32 codebooks. The speech decoder of Mimi takes the reconstructed representation (one vector every 80 ms) and decodes the waveform back.
To align Mimi's continuous speech representations with text embeddings (i.e., turning time-sync into text-sync representation), we add a cross-attention network to the encoder, explicitly targeting the text token length. Simultaneously, the causal transformer decoder uses force-aligned signals to map the cross-attention output back to the continuous latent space (for reconstruction or speech generation purpose). By doing this (well we still have to train the cross-attention and the causal decoder), we turn time-sync Mimi tokenizer into text-sync Mimi tokenizer.
An additional encoder (4-layer, 16.8M parameters) that aligns Mimi's speech representations with text embeddings (we use the Llama3 embeddings, specifically from meta-llama/Llama-3.1-8B-Instruct). It maps the audio sequence to the semantic token space via a cross-attention bottleneck:
- Input:
- Key & Value: Mimi's time-sync speech representation (length T)
- Query: Llama's text embedding (length N)
- Output: Text-synchronous speech representation (length N)
The causal transformer decoder (4-layer, 12.6M parameters) reconstructs the time-synchronous latents from the text-synchronous representations. Given the encoder’s output [ti, si] for each text token, the decoder must produce a variable-length sequence of Mimi latent vectors [z(i,1), z(i,2), …, z(i,Ti)] for each token—where Ti depends on how many speech frames correspond to the i-th text token.
Force Alignment (Training Only)
To train this decoder, we need to know the mapping between text tokens and speech frames—i.e., which consecutive time-synchronous frames [z(i,1), …, z(i,Ti)] correspond to each text token i. We obtain this via force alignment: given an audio file and its text transcript, force alignment produces character-level timestamps, which we then map to subword token boundaries.
In practice, we use WhisperX (backed by wav2vec2 alignment models) to obtain character-level alignments, and then aggregate them to match the Llama tokenizer’s subword segmentation. This gives us the start/end timestamps for each subword token, which we use to slice the Mimi encoder’s output into per-token groups. The alignment was performed on LibriSpeech (960 hours) and LibriTTS (585 hours) for the English data used in this work.
Important: Force alignment is needed only during training to construct the target sequences. At inference time, the decoder autoregressively generates z-frames and uses a learned stop token to determine when to stop generating z-frames for the current token and proceed to the next—no alignment information is required at inference.
Decoder Sequence
With the per-token frame counts from force alignment, we construct a flattened sequence that interleaves the text-synchronous representations with the time-synchronous latents. The causal transformer is trained to predict this joint continuous sequence autoregressively (left-to-right):
More concretely, the repeating unit for each token i in the flattened sequence is:
<|text_speech_start|> [t_i] [s_i] <|text_speech_end|> <|time_speech_start|> [z_(i,1)] [z_(i,2)] ... [z_(i,T_i)] <|time_speech_end|>
At each step, the decoder predicts the continuous latent z directly (minimizing the L2-norm), so the predicted vectors can be fed into the frozen Mimi decoder for waveform generation. The <|time_speech_end|> token is trained with a binary cross-entropy loss to signal when to stop generating z-frames for the current token and proceed to the next.
Streaming decoding: Because the causal transformer operates left-to-right, the decoding process is naturally streamable. As soon as each z-frame is predicted, it can be immediately passed to the frozen Mimi decoder to produce audio—there is no need to wait for the entire sequence to be generated before starting waveform synthesis.